TABLA DE CONTENIDO
INTRODUCCIÓN
La ingeniería del software es una materia que día a día va creciendo, conforme crece la tecnología y la demanda de los usuarios por programas que tecnifiquen los procesos tanto empresariales como personales. Los avances tecnológicos, la globalización obligan a los programadores a cada momento crear nuevas propuestas de aplicaciones, programas para sus clientes. Igualmente el software facilita la adaptación rápida de productos y servicios a diferentes sectores del mercado, para soportar la coordinación global multicultural de las empresas.
A pesar de la investigación y el desarrollo de técnicas y métodos en ingeniería del software son constantes y suelen suponer interesantes avances en la resolución de problemas de desarrollo de software. Uno de los problemas que se están presentando es el desorden, falta de poner en práctica lo que se tiene para aplicar en la ingeniería de software y por ende los ingenieros, se están convirtiendo prácticamente en albañiles , los cuales cada uno aplica lo que quiere para crear los programas. Pero esto no quiere decir que sea lo correcto, todo lo contrario los conceptos y herramientas de Ingeniería del Software están para seguirse todas, lo que garantizara productos de calidad y que satisficieran completamente las necesidades de los usuarios.
En este trabajo realizamos una consulta del futuro que le espera a la ingeniería del software, para lo cual debemos primero conocer su historia, su presente, y principales conceptos que intervienen.
Entre el periodo de la informática comprendido entre 1960 - 1990, el principal desafío era el desarrollo del hardware de computadoras, de forma que se redujera el costo del procesamiento y almacenamiento de datos. A lo largo de las décadas de los ochenta, los avances en microelectrónica han dado como resultado una mayor potencia de cálculo a la vez que una reducción del costo. Hoy, el problema es diferente. El principal desafío es mejorar la calidad (y reducir el costo) de las soluciones basadas en computadoras soluciones que se implementan con el software.
En la década de los sesenta, menos del 1 por 100 de la gente podría describir de forma inteligente lo que significaba el “software de computadora”. Hoy, la mayoría de los profesionales y muchas personas en general creen que entienden el software. Una descripción del software de un libro de texto puede tener la siguiente forma: “Software” (1) instrucciones (programas de computadora) que cuando se ejecutan proporcionan la función y el comportamiento deseado, (2) estructuras de datos que facilitan a los programas manipular los datos adecuadamente la información, y (3) documentos que describen la operación y el uso de los programas”.
Asimismo la importancia del software de computadora se puede enunciar de muchas formas. El software se caracterizaba como diferenciador. La función proporcionada por el software es lo que diferencia a los productos, sistemas y servicios, y proporciona una ventaja competitiva en el mercado. Sin embargo, el software es más que un diferenciador. Los programas, documentos y datos que constituyen el software ayudan a generar la mercancía más importante que pueda adquirir cualquier individuo, negocio o gobierno –la información-. Pressman y Herron [PRE9 11 describen el software de la forma siguiente:
El software de computadora es una de las pocas tecnologías clave que tendrán un impacto significativo en los años 90. Se trata de un mecanismo para automatizar negocios, industrias y gobiernos, un medio para transferir nuevas tecnologías, un método para adquirir experiencia valiosa que otras personas puedan utilizar, un medio para diferenciar los productos de una compañía de los productos de los de sus competidores, y una ventana que permite examinar el conocimiento colectivo de una corporación. El software es crucial para casi todos los aspectos del negocio. Pero de muchas maneras, el software es también una tecnología oculta. Encontramos el software (frecuentemente, sin darnos cuenta) cuando nos desplazamos hasta nuestro trabajo, cuando efectuamos cualquier compra, cuando nos detenemos en el banco, cuando hacemos una llamada telefónica, cuando visitamos al médico o cuando realizamos cualquiera de los cientos de actividades diarias que reflejan la vida moderna.
El software está en todas partes y, sin embargo, hay muchas personas en puestos de responsabilidad que tienen poca o ninguna comprensión de lo que realmente es, como se construye, o de lo que significa para las instituciones que lo controlan (y a las que controla). Y, lo que es más importante, tienen muy poca idea de los peligros y oportunidades que este software ofrece.
La omnipresencia del software nos lleva a una conclusión sencilla: siempre que una tecnología tiene un impacto amplio -un impacto que puede salvar vidas o ponerlas en peligro, construir negocios o destruirlos, informar a los jefes de gobierno o confundirlos-, es preciso «manejarla con cuidado».

Hoy en día el software tiene un doble papel. Es un producto, pero simultáneamente es el vehículo para hacer entrega de un producto. Como producto permite el uso del hardware, ya sea, por ejemplo, un ordenador personal o un teléfono móvil celular. Como vehículo utilizado para hacer entrega del producto, actúa como base de control, por ejemplo un sistema operativo, o un sistema gestor de redes. El software hace entrega de lo que se considera como el producto más importante del siglo veintiuno, la información. El software transforma datos personales para que sean más útiles en un entorno local, gestiona información comercial para mejorar la competitividad, proporciona el acceso a redes a nivel mundial, y ofrece el medio de adquirir información en todas sus formas.
Actualmente se considera la Ingeniería del Software como una nueva área de la ingeniería, y la profesión de ingeniero informático es una de las más demandadas, aunque en España los salarios suelen ser bajos para la cualificación de estos profesionales. La palabra ingeniería tiene una connotación de prestigio que provoca que muchas ramas del conocimiento tiendan a autodenominarse así.
La ingeniería del software trata áreas muy diversas de la informática y de las Ciencias de la Computación, aplicables a un amplio espectro de campos, tales como negocios, investigación científica, medicina, producción, logística, banca, meteorología, derecho, redes, entre otras muchas.
Actualmente se considera la Ingeniería del Software como una nueva área de la ingeniería, y la profesión de ingeniero informático es una de las más demandadas, aunque en España los salarios suelen ser bajos para la cualificación de estos profesionales. La palabra ingeniería tiene una connotación de prestigio que provoca que muchas ramas del conocimiento tiendan a autodenominarse así.
La ingeniería del software trata áreas muy diversas de la informática y de las Ciencias de la Computación, aplicables a un amplio espectro de campos, tales como negocios, investigación científica, medicina, producción, logística, banca, meteorología, derecho, redes, entre otras muchas.
Por otra parte La gran mayoría de los sistemas de software creados hoy en día son los llamados sistemas corporativos; es decir, son orientados a formar una parte importante de los negocios de las grandes empresas.
Continuando en nuestro contexto, se identifica un nuevo enfoque del problema de desarrollo, el apoyo en la sincronización de los procesos de negocio, estructuras complejas de información manejada por el negocio, todo esto entrelazado por restricciones dadas por las reglas del negocio. La tecnología actual, por otro lado, ha alejado más todavía los ingenieros de las máquinas, sistemas operativos, incluso de las tareas de programación.
El enfoque de la mayoría de los equipos de desarrollo e ingenieros, participes en proyectos, sigue siendo con un bajo nivel de abstracción, cerca de la codificación. Se tiende a pensar en la base de datos a utilizar, establecer la navegación de las páginas, programar los protocolos de comunicación, etc. Esto lleva a utilizar las tareas de programación y de pruebas para validar el entendimiento y cumplimiento de la funcionalidad de los sistemas.
Lo anteriormente expuesto muestra un problema metodológico, consecuencia de un desfase entre el enfoque teórico óptimo (análisis de negocio) y el enfoque práctico real (programación y pruebas) en los proyectos de hoy. En otras palabras, la metodología actualmente usada está atrasada con respecto al avance tecnológico.
Desarrollando más esta idea, se identifican algunos problemas concretos de las metodologías:
Ellas no obligan a sus ejecutores a respetar todas las normas y los procedimientos establecidos, especialmente en las etapas tempranas del proyecto. Es muy fácil y tentador “saltar” una o más de estas etapas, uno o más documentos o modelos, pasando directamente a implementación, producción y posterior corrección de los sistemas desarrollados.
Control de calidad del producto final. La codificación y complejidad del programa, es demasiada para ser revisada y verificada fehacientemente. Por otro lado, los códigos fuentes y los ejecutables actualmente son los únicos entregables eficientemente verificables.
Estos dos problemas al parecer forman una situación contradictoria: la metodología tradicional no permite validar eficientemente la calidad de los sistemas antes de llegar al código fuente y, por otro lado, tampoco permite llegar eficientemente a códigos fuentes de calidad.
La Ingeniería del Software se podría definir como el establecimiento y aplicación de principios de la Ingeniería para obtener software. Teniendo en cuenta factores tan importantes como el coste económico, la fiabilidad del sistema y un funcionamiento eficiente que satisfaga las necesidades del usuario.
El proceso de ingeniería de software se define como "un conjunto de etapas parcialmente ordenadas con la intención de lograr un objetivo, en este caso, la obtención de un producto de software de calidad" [Jacobson 1998].El proceso de desarrollo de software" es aquel en que las necesidades del usuario son traducidas en requerimientos de software, estos requerimientos transformados en diseño y el diseño implementado en código, el código es probado, documentado y certificado para su uso operativo". Concretamente "define quién está haciendo qué, cuándo hacerlo y cómo alcanzar un cierto objetivo" [Jacobson 1998].
El proceso de desarrollo de software requiere por un lado un conjunto de conceptos, una metodología y un lenguaje propio. A este proceso también se le llama el ciclo de vida del software, que comprende las etapas por las que pasa un proyecto software desde que es concebido, hasta que está listo para usarse. Típicamente, incluye las siguientes etapas: toma o elicitación de requisitos, análisis, diseño, desarrollo, pruebas (validación, aseguramiento de la calidad), instalación (implantación), uso, mantenimiento y actualización.
La ingeniería de software comprende:
Ciclo de desarrollo de software.
Metodologías para el desarrollo de software (RUP, utilización de patrones, framework).
Gestión de proyectos.
Evaluación de tecnología y/o arquitecturas para la toma de decisiones.
El software necesario para los sistemas de alta tecnología cada vez es más difícil a medida que van pasando los años y el tamaño de los programas resultantes incrementa de manera proporcional. El crecimiento rápido del tamaño del programa «promedio» nos presentará unos cuantos problemas si no fuera por el simple hecho de que: a medida que el programa aumenta, el número de personas que deben trabajar en él también aumenta.
La experiencia indica que a medida que aumenta el número de personas de un equipo de proyecto de software, es posible que la productividad global del grupo sufra. Un método para resolver este problema es crear un número de equipos de ingeniería del software, por el que se compartimen-talicen las personas en grupos de trabajo individuales. Sin embargo, a medida que el número de equipos de ingeniería del software aumenta, la comunicación entre ellos es tan difícil y larga como la comunicación entre individuos. Es aún peor, la comunicación (entre individuos o equipos) -es decir, es demasiado tiempo el que se pasa transfiriendo poco contenido de información, y toda esta información importante suele «perderse entre las grietas»-.
Si la comunidad de ingeniería del software va a tratar el dilema de la comunicación de manera eficaz, el futuro de los ingenieros deberá experimentar cambios radicales en la forma en que los individuos y los equipos se comunican entre sí. El correo electrónico, los tablones de anuncios y los sistemas de videoconferencia son los lugares comunes como mecanismos de conexión entre muchas personas de una red de información.
La importancia de estas herramientas en el contexto del trabajo de la ingeniería del software no se puede sobrevalorar.
Con un sistema de correo electrónico o de tablón de anuncios eficaz, el problema que se encuentra un ingeniero del software en la ciudad de Nueva York, se puede resolver con la ayuda de un compañero en Tokio. En realidad, los tablones de anuncios y los grupos de noticias especializados se convierten en los depósitos de conocimiento que permiten recoger un conocimiento colectivo de un grupo grande de técnicos para resolver un problema técnico o un asunto de gestión.
El vídeo personaliza la comunicación. Y lo mejor es que hace posible que compañeros en lugares diferentes (o en continentes diferentes) se «encuentren» regularmente. Pero el vídeo también proporciona otra ventaja: Se puede utilizar como depósito para conocimiento sobre el software y para los recién llegados a un proyecto. La evolución de los agentes inteligentes también cambiará los patrones de trabajo de un ingeniero del software ampliando dramáticamente las herramientas
Del software. Los agentes inteligentes mejorarán la habilidad de los ingenieros mediante la comprobación de los productos del trabajo utilizando el conocimiento específico del dominio, realizando tareas administrativas, llevando a cabo una investigación dirigida y coordinando la comunicación entre personas.
Finalmente, la adquisición de conocimiento está cambiando profundamente. En Internet, un ingeniero del software puede subscribirse a un grupo de noticias centrado en áreas de tecnología de inmediata preocupación. Una pregunta enviada a un grupo de noticias provoca respuestas de otras partes interesadas desde cualquier lugar del globo. La World Wide Web proporciona al ingeniero del software la biblioteca más grande del mundo de trabajos e informes de investigación, manuales, comentarios y referencias de la ingeniería del software'.
Si la historia pasada se puede considerar un indicio, es justo decir que las mismas personas no van a cambiar. Sin embargo, las formas en que se comunican, el entorno en el que trabajan, la forma en que adquieren el conocimiento, los métodos y herramientas que utilizan, la disciplina que aplican, y por tanto, la cultura general del desarrollo del software sí cambiarán significativa y profundamente. (Roger Pressman, 2002, 574).
Las personas que construyen y utilizan software, el proceso de ingeniería del software que se aplica, y la información que se produce se ven afectados todos ellos por los avances en la tecnología del hardware y software. Históricamente, el hardware ha servido como impulsor de la tecnología de la computación. Una nueva tecnología de hardware proporciona un potencial.
Entonces los constructores de software reaccionan frente a las solicitudes de los clientes en un intento de aprovechar ese potencial. Las tendencias futuras de la tecnología del hardware tienen probabilidades de progresar en dos rutas paralelas. En una de las rutas, las tecnologías de hardware seguirán evolucionando rápidamente. Mediante la mayor capacidad que proporcionan las tecnologías de hardware tradicionales, las demandas efectuadas a los ingenieros de software seguirán creciendo.
Pero los cambios verdaderos de la tecnología de hardware se pueden producir en otra dirección. El desarrollo de arquitecturas de hardware no tradicionales (por ejemplo, máquinas masivamente paralelas, procesadores ópticos y máquinas de redes neuronales, pueden dar lugar a cambios radicales en la clase de software que se puede construir y también a cambios fundamentales en nuestro enfoque de la ingeniería del software. Dado que estos enfoques no tradicionales siguen estando en el primer segmento del ciclo de quince años, resulta difícil predecir la forma en que el mundo del software se modificará para adaptarse a ellas.
Las tendencias futuras de la ingeniería del software se verán impulsadas por las tecnologías de software. La reutilización y la ingeniería del software basada en componentes (tecnologías que todavía no están maduras) ofrecen la mejor oportunidad en cuanto a mejoras de gran magnitud en la calidad de los sistemas y se encuentran en el momento de comercializarse. De hecho, a medida que pasa el tiempo, el negocio del software puede empezar a tener un aspecto muy parecido al que tiene el negocio del hardware en la actualidad. Quizá existan fabricantes que construyan dispositivos diferentes (componentes de software reutilizables), otros fabricantes que construyan componentes de sistemas (por ejemplo, un conjunto de herramientas para la interacción hombremáquina) e integradores de sistemas que proporcionen soluciones para el usuario final.
Resulta inconcebible un procesador de textos que no sea capaz de corregir nuestra ortografía, o sugerir sinónimos. Incluso en muchos casos corrigen el estilo de lo que escribimos. Existen al menos una docena de juegos de video en los que los enemigos controlados por el ordenador exhiben una “inteligencia” tal, que resultan prácticamente imposibles de vencer. Y en algunos juegos de mesa un programa de ordenador es el campeón absoluto e imbatible.
Las interfaces que el software emplea para comunicarse con el usuario también han cambiado para mejor. Hemos padecido enormes paneles de luces de colores que representaban el contenido de la memoria en un momento determinado, terminales que imprimían sus respuestas en papel, tubos de rayos catódicos plagados de mensajes crípticos y modernos LCD llenos de ventanas e iconos. Por fin estamos haciendo avances reales en la forma en que interactuamos con nuestros programas: rostros robóticos capaces de expresar decenas de emociones, sistemas que reconocen órdenes verbales o incluso dispositivos capaces de interpretar los movimientos de nuestro cuerpo.
Todas estas mejoras, junto a los continuos avances realizados en la capacidad del hardware, permitirán el desarrollo de un nuevo tipo de software. No estamos hablando de una súper planilla de cálculo o un formidable procesador de textos. Estamos pensando en un “ente” que reaccione ante nuestra presencia y palabras tal como lo haría un ser vivo. Nos referimos al fin del software tal como lo conocemos, y el nacimiento de algo más parecido al HAL9000 de la película “2001”.
La incorporación de tecnologías hápticas y sistemas de reconocimiento de voz hará que hacia el 2009 los teclados comiencen a desaparecer de los escritorios. Los documentos se crearán oralmente, y los programas se controlaran mediante gestos corporales o “toques” sobre una pantalla virtual. Si has visto la película "Minority Report" tienes una buena idea de a que nos referimos.
La incorporación de tecnologías hápticas y sistemas de reconocimiento de voz hará que hacia el 2009 los teclados comiencen a desaparecer de los escritorios. Los documentos se crearán oralmente, y los programas se controlaran mediante gestos corporales o “toques” sobre una pantalla virtual. Si has visto la película "Minority Report" tienes una buena idea de a que nos referimos.
Pero la Ley de Moore que predice la duplicación de la capacidad de procesamiento de los ordenadores cada 18 meses no se detiene, y el hardware será capaz de albergar software cada vez más complejo. Aproximadamente en el 2020, ya sobre el límite de la miniaturización permitida por las leyes de la física cuántica, los ordenadores correrán programas de IA con una capacidad similar a la de un cerebro humano. Si sostuviésemos una conversación sobre cualquier tema con un software de esa época, creeríamos que estamos hablando con un humano.
Pocos años más tarde, de la mano de un hardware compuesto por chips cuánticos masivamente paralelos (con cientos de núcleos corriendo a la par), el software será incluso superior al más inteligente de los humanos. Más allá de la discusión filosófica de si serán conscientes de sí mismos o no, estos programas podrán abordar problemas de ingeniería, física o demografía mejor que cualquier experto humano. Cada alumno del futuro tendrá un “maestro” particular, que no será más que un software con personalidad propia, adaptada a su estudiante y especializado en los temas que el niño necesite aprender.
Pocos años más tarde, de la mano de un hardware compuesto por chips cuánticos masivamente paralelos (con cientos de núcleos corriendo a la par), el software será incluso superior al más inteligente de los humanos. Más allá de la discusión filosófica de si serán conscientes de sí mismos o no, estos programas podrán abordar problemas de ingeniería, física o demografía mejor que cualquier experto humano. Cada alumno del futuro tendrá un “maestro” particular, que no será más que un software con personalidad propia, adaptada a su estudiante y especializado en los temas que el niño necesite aprender.
Gran parte del software migrará desde los ordenadores hacia los más diversos aparatos. Coches, trenes, barcos, electrodomésticos, y casi todo lo que puedas imaginar, tendrán incorporada una “personalidad” propia. Este software de IA será el que determine las posibilidades reales de estos mecanismos. El gadget perfecto estará en todas partes. Nuestro refrigerador conocerá nuestros gustos (y el estado de nuestra cuenta bancaria), y encargará de hacer las compras necesarias para reponer los faltantes.
Algunos artefactos muy comunes, que ya parecen haber dado todo de sí, mejoraran su desempeño. Imagina que el software residente en tu grabadora de video (HD-DVD o alguno de sus sucesores) conozca tus gustos sobre cine, y se encargue de grabar las películas que encajen con tus aficiones a medida que las emiten por los canales de cable. O que recopile las noticias sobre deportes, ciencia o política que tanto te gusta a ver al llegar a casa. Todo esto es posible con el software adecuado. Una IA con la inteligencia de un niño podría hacerlo con facilidad.
A mediados de este siglo, los mecanismos del cerebro humano habrán dejado de ser un secreto, y la nanotecnología será una ciencia dominada, que proporcionara chips increíblemente complejos en un espacio sumamente pequeño. El software (o parte de él) será implantado en nuestro cerebro, comunicándose directamente con el usuario mediante imágenes, sonidos, olores o sensaciones táctiles que introducirán directamente en las regiones apropiadas de la mente. Los “Microsoft” descriptos por William Gibson en sus novelas ciberpunk serán una realidad.
Claro, también esperamos con ansías la carga de conocimientos a la Matrix global. Cuando podamos transferir nuestras memorias a un ordenador, el siguiente paso evolutivo estará listo: nosotros mismos seremos software.
A mediados de este siglo, los mecanismos del cerebro humano habrán dejado de ser un secreto, y la nanotecnología será una ciencia dominada, que proporcionara chips increíblemente complejos en un espacio sumamente pequeño. El software (o parte de él) será implantado en nuestro cerebro, comunicándose directamente con el usuario mediante imágenes, sonidos, olores o sensaciones táctiles que introducirán directamente en las regiones apropiadas de la mente. Los “Microsoft” descriptos por William Gibson en sus novelas ciberpunk serán una realidad.
Claro, también esperamos con ansías la carga de conocimientos a la Matrix global. Cuando podamos transferir nuestras memorias a un ordenador, el siguiente paso evolutivo estará listo: nosotros mismos seremos software.

7.1 Origen, filosofía y futuro del Software Libre.
El software Libre tiene como finalidad de que nadie, absolutamente nadie, se apropie de la propiedad intelectual de éste. Es decir, el software libre no pertenece a nadie, pertenece a todos los que lo desarrollan y a los que lo utilizan, y todos pueden contribuir para mejorarlo. Evelio Martínez.
Últimamente en el mundo de la computación se ha escuchado con regularidad el término Software Libre. Más que un movimiento liberador del software, es una filosofía de compartir aquello que nos es útil, en este caso el código fuente o programas de cómputo. Estas aplicaciones o piezas de software nos facilitan una serie de actividades en nuestra computadora sin pagar algún costo por utilizarlas.
Hoy en día disponemos de una gran variedad de opciones en cuanto a software se refiere. Podemos emplear programas comerciales que nos facilitan el realizar tareas como escribir una carta, editar alguna fotografía o enviar un correo electrónico. Sin embargo ¿Qué ocurre cuando queremos compartir ese mismo software con algún amigo?, ¿Qué pasa si queremos modificarlo o pagar para que alguien más lo modifique por nosotros con el fin de adaptarlo a nuestras necesidades? Simplemente no es posible, porque no tenemos acceso al código fuente; y si distribuimos dicho software sin el permiso del autor (o autores) estamos incurriendo en un delito. Es aquí donde tiene cabida el movimiento del software libre, software cuya distribución, uso y modificación es perfectamente legal y no solo eso, sino que además nos incita a “compartir” como parte fundamental de su filosofía, siempre a favor de mejorar el software.
En esta primera parte de este artículo nos enfocaremos a conocer los orígenes del software libre, mencionando sus principales autores. En las siguientes ediciones nos enfocaremos a describir la filosofía de este movimiento. También hablaremos sobre su futuro, las licencias de software y el debate mundial de patentar el software y sus repercusiones en la industria de la informática. Mencionaremos también algunas de las aplicaciones que utilizan el concepto de bazar del software libre.
7.1.2 Orígenes del Software Libre.
La primera generación de computadoras aparece a finales de la década de 1940. Eran de enormes dimensiones y muy costosas. El poder computacional era muy pobre comparado con las computadoras de la actualidad. La relación entre el hardware y el software era demasiado estrecha, los programas se escribían de una manera bastante especializada (lenguaje de máquina) y por lo tanto, el concepto de software como una parte “independiente” del hardware se veía todavía muy lejano. Debido precisamente a esta relación entre hardware-software, las personas que operaban las computadoras debían de poseer cierto nivel de conocimientos sobre el funcionamiento de las mismas, así como de los programas que necesitaban para hacerlas funcionar. En ese entonces no existían los usuarios convencionales, todos eran usuarios especializados, en su gran mayoría científicos o ingenieros.
Entre esos usuarios expertos, era muy común que se diera el intercambio de programas así como el compartir mejoras hechas a los mismos. A estas mejoras en el software se les conoce como hacks y a estos primeros expertos o gurus de la programación se les empezó a llamar hackers. Término que en la actualidad se ha ido desvirtuando, confundiéndolos con delincuentes informáticos. En general a los hackers les interesa conocer el funcionamiento detallado de los sistemas informáticos y de su seguridad, manteniendo una actitud ética. Algunos traspasan esta línea y se convierten en lo que la comunidad hacker ha denominado cracker.
En los inicios de la computación, 40s y 50s, no existían las licencias de software. El software era libre y los programas se intercambiaban como se hace con las recetas de cocina. Este espíritu perduró en la comunidad de programadores durante años como algo natural, hasta que con el tiempo las restricciones derivadas de licencias de uso, implementadas por desarrolladores de software y las grandes compañías, plantearon la necesidad de fijar una línea divisora entre el software libre y el software propietario.
Posteriormente, el software se empezó a ver más como una gran colección de pequeños fragmentos de código, susceptible de ser modificado y adaptado. Las computadoras de escritorio empezaban a volverse cada vez más populares y accesibles a un número mayor de personas. Había también una mayor cantidad de programadores probando cosas nuevas, escribiendo sus propias aplicaciones e iniciando una gran variedad de proyectos. Sin embargo, había una importante limitante, la gran mayoría del software que se utilizaban en ese momento era propietario y venía protegido por licencias que regulaban su uso y distribución.
Con el surgimiento del ARPANET (precursor del Internet) a finales de la década de los 60s –la cual permitía la interconexión entre redes de computadoras de las diversas universidades– empezó el surgimiento de la primera comunidad global que se alzaba sobre los valores y principios del software libre. Los grupos hasta entonces dispersos de hackers, pudieron a través de la red, sumar esfuerzos, intercambiar conocimientos y colaborar entre sí. Los proyectos involucraban cada vez más desarrolladores de software, quienes estaban dispersos geográficamente alrededor del mundo y utilizaban el correo electrónico como medio de comunicación para hacer llegar sus aportaciones.
La aportación de UNIX al software libre. Los orígenes del sistema operativo UNIX se remontan a finales de los años 60s. UNIX en sus inicios fue un proyecto de investigación por parte de los laboratorios Bell de AT&T. El propósito era desarrollar un sistema operativo simple y elegante, además se quería evitar que estuviera completamente escrito en ensamblador, lo que motivó el nacimiento del lenguaje de programación C.
Con el transcurrir de los años el sistema operativo fue ganando adeptos y aumentando su popularidad entre los usuarios. A finales de los años 70s, AT&T creó un grupo con la misión de comercializar el sistema operativo: el UNIX Support Group (USG). El problema que surgió fue que las licencias, que un principio habían sido libres de cualquier costo, o a precios relativamente bajos, se fueron encareciendo. Éstas incluían cada vez más restricciones, limitando el uso y las posibles mejoras que se pudieran hacer al sistema operativo. Además, estas políticas provocaron que prácticamente cualquier empresa grande de software de aquel entonces, dispusiera de su propia versión de UNIX. Esto provocó que las mismas fueran hasta cierto punto incompatibles y se entorpeciera la posibilidad de aprovechar el conocimiento sobre UNIX de otro fabricante.
Algunas de las versiones de UNIX y sus empresas comercializadoras eran: AIX de IBM, HP-UX de Hewlett-Packard, Solaris y SunOS de Sun Microsystems, IRIX de Silicon Graphics, entre otras. El principal elemento en contra de los sistemas operativos UNIX (no libres) es el costo de propiedad intelectual que puede variar según el proveedor y según la plataforma de equipo de cómputo a instalar. Asimismo, el licenciamiento es generalmente por usuario, cayendo así en un esquema de incrementos de costos cada vez que la empresa crece en personal y en requerimientos.
Al mismo tiempo que UNIX se licenciara comercialmente a diversas empresas, empezaron a emerger sistemas operativos (basados en UNIX) gratuitos, pero con algunas restricciones. En esta categoría caen los BSD (Berkeley System Distribution). La rama BSD (NetBSD, FreeBSD y OpenBSD) se origina cuando At&T licenció el código original de UNIX a la Universidad de Berkeley en California. Ingenieros de Berkeley hicieron mejoras significativas a UNIX generando su propia versión. Se creó entonces una condición divergente entre la versión original de AT&T (denominada ya en ese momento “UNIX System V”) y la versión de Berkeley: BSD.
El grupo que llevaba el desarrollo de BSD, por su parte, decidió eliminar todo el código de AT&T de su sistema, reemplazándolo por otro que no estuviera sujeto a pago de licencias, esto derivó en el 4.4BSD-Lite, un sistema libre de las restricciones impuestas por el USG. Posteriormente originó el desarrollo de FreeBSD: UNIX BSD, OpenBSD, NetBSD y Darwin (base del sistema operativo MacOS X). BSD tiene una licencia que permite realizar modificaciones y no redistribuir su código, lo cual genera ciertas restricciones para utilizarla en proyectos libres.
Richard Stallman y el proyecto GNU/Linux, “Necesitamos reforzar el espíritu de colaboración de la gente, respetando su libertad para cooperar y evitando imponer esquemas para dividirlos y dominarlos.” Richard Stallman.
Si sé está hablando de software libre es prácticamente imposible no mencionar a Richard Stallman, un personaje genial y controvertido, imprescindible para comprender la verdadera esencia del software libre. Físico de carrera, graduado en la Universidad de Harvard. Trabajó en el laboratorio de inteligencia artificial del Instituto Tecnológico de Massachussetts (MIT) desde 1971.
Una de las anécdotas que se cuentan entorno a Richard Stallman, narra que en cierto lugar donde él trabajaba, tenían una impresora que atoraba continuamente el papel. La única manera de verificar que se atoraba el papel, era trasladarse físicamente hasta el lugar donde estaba dicho dispositivo. Stallman tuvo la idea de modificar el código que controlaba la impresora, para que ésta mandara un aviso cuando se atascara el papel y evitarse estar revisándola a cada rato. Para ello se comunicó con las personas que distribuían el software de la impresora y les planteó lo que quería hacer. Lo único que obtuvo como respuesta, fue que era imposible que le dieran acceso al código fuente del programa que controlaba la impresora, y por lo tanto no podía modificarlo. Stallman se hizo la siguiente pregunta. ¿Cómo es posible que no pueda hacer una mejora a un software por el que pagué?
En 1984 movido por el deseo de lograr que el código fuente del software esté disponible para cualquiera, abandonó el MIT para iniciar el proyecto conocido como GNU. El proyecto GNU tenia la finalidad de crear un sistema operativo completamente libre. En 1985 publicó su manifiesto GNU, en el cual expone sus intenciones y motivaciones para crear una alternativa libre al Unix a la cual llamó GNU (GNU No es UNIX). Poco tiempo después se integró a la Free Software Foundation (FSF) para coordinar el esfuerzo del software libre. La influencia y liderazgo de Stallman para establecer un marco de referencia moral, político y legal del movimiento de software libre, como alternativa al software propietario.
Una contribución de Richard Stallman al movimiento del software libre es inventar el concepto de copyleft (contrario a copyright). Elemento clave en la propuesta de la Licencia Pública General de GNU, conocida por sus siglas en inglés, GPL/GNU.
En 1990 el sistema operativo GNU estaba casi completo, el único componente que faltaba era el núcleo (kernel), también llamado Hurd. Un año después, en 1991, Linus Torvalds, un estudiante finlandés frustrado por tener que usar MS-DOS y queriendo evitar las limitaciones de MINIX, envió un mensaje por Internet al grupo de noticias comp.os.minix en el cual mencionaba que estaba trabajando en un versión libre similar a MINIX. Éste era un sistema operativo bastante reducido creado por Andrew Tanenbaum con fines didácticos, el sistema era bastante simple y con pocas funcionalidades.
Torvalds ponía a disposición (en la red Internet) esta versión de Minix, para quien la quisiera usar y a su vez invitaba a realizar aportaciones que sirvieran para mejorarla. A partir de ese momento y empleando los componentes desarrollados por el proyecto GNU y la Internet como vehículo de comunicación, Linus consiguió convertirse en el líder de una comunidad de desarrolladores diseminada por todo el mundo. Al sistema operativo desarrollado por Linus con ayuda de la comunidad, se le designó el nombre de Linux, en honor al esfuerzo de Torvalds. Con el núcleo de Linux y con la mayor parte del sistema GNU completada, y respaldado por la licencia GPL (General Public License), la cual se sustenta sobre el concepto de “copyleft”, la primera versión del sistema operativo GNU/Linux se libera en septiembre de 1991.
Lo interesante del sistema operativo Linux, no era ni su diseño ni tampoco su filosofía, sino su metodología de desarrollo de software. En ese entonces el software se escribía en grupos cerrados, mientras que Linus Torvalds proponía un modelo distribuido, abierto, y cualquier persona interesada en contribuir al software podría participar. A este modelo en el cual se desarrolla Linux y la mayoría del software libre se le conoce como bazar. Al modelo tradicional empleado por las compañías desarrolladoras de software propietario se le conoce como catedral. Este concepto lo explica más detalladamente Eric S. Raymond en un ensayo titulado La Catedral y El Bazar, el cual pueden encontrar en la red. Eric S. Raymond es también uno de los personajes importantes del movimiento software libre y Open Source. Con el transcurrir del tiempo surgieron pequeñas compañías que empezaron a empaquetar en un conjunto de disquettes (hoy CDs/DVDs) el núcleo de Linux provisto con una interfase gráfica, acompañado con programas de GNU y utilerías de software libre, con lo que se facilitaba su instalación. A estos conjuntos de CD/DVD se les denomina Distribuciones de GNU/Linux. Estas distribuciones de software libre bajo licencia GPL/GNU son desarrolladas por empresas de software como Red Hat y SuSE. Otras distribuciones son desarrolladas por organizaciones de programadores voluntarios, tales como Debian, Ubuntu, Gentoo, entre otras.
El Software libre a lo largo de estos años no ha dejado de crecer y multiplicarse. Existen en la red de Internet miles de desarrolladores de software dispuestos a contribuir para la causa de este movimiento.
En la segunda parte de este artículo nos enfocaremos a explicar la filosofía de este movimiento, las licencias de software y mencionaremos algunas de las principales aplicaciones de software libre que existen en la red.
Orlando Jorge Franco Murillo y Evelio Martínez Martínez son: estudiante y profesor-investigador respectivamente de la carrera de Licenciado en Ciencias Computacionales, perteneciente a la Facultad de Ciencias de la Universidad Autónoma de Baja California (UABC) en la ciudad de Ensenada.
7.1.3 Filosofía del Software Libre.
En la edición pasada hablamos sobre los orígenes del movimiento de software libre. También mencionamos los dos modelos de desarrollo de software: bazar y catedral, y comentábamos que el modelo bazar era el que se utilizaba para crear software libre, en donde participaban voluntariamente miles de desarrolladores diseminados en todo el mundo. Mientras que el modelo catedral es utilizado por grupos pequeños de desarrolladores, generalmente para crear software propiedad de una compañía.
En esta segunda parte hablaremos sobre los principios, filosofía y licencias en la que se basa el software libre. Abordaremos también las diferencias entre Software Libre y Open Source. Al final mencionaremos algunos de proyectos de software libre que les podrían ser de utilidad a personas que quieran enriquecer el contenido y administración de páginas web.
7.1.4 Principios y filosofía del Software Libre.
Richard Stallman, pionero de este movimiento a nivel mundial, aclara que software libre (Free Software) es un asunto de libertad. La palabra “free” en inglés se malinterpreta como “gratis” o libre de costo. La palabra “free” se refiere a la libertad de los usuarios de poder ejecutar, copiar, distribuir, estudiar, cambiar y mejorar el software.
Para entender un poco mejor este concepto, se establecieron estas 4 libertades para los usuarios de este tipo de software.
* La libertad de usar el programa, con cualquier propósito (libertad 0).
* La libertad de estudiar cómo funciona el programa y adaptarlo a tus necesidades (libertad1).
* La libertad de distribuir copias, con lo que puedes ayudar a la comunidad (libertad 2).
* La libertad de mejorar el programa y hacer públicas las mejoras a los demás, de modo que toda la comunidad se beneficie. (libertad 3).
* La libertad de distribuir copias, con lo que puedes ayudar a la comunidad (libertad 2).
* La libertad de mejorar el programa y hacer públicas las mejoras a los demás, de modo que toda la comunidad se beneficie. (libertad 3).
Es software libre, entonces, aquel que cumple estas cuatro libertades. El acceso al código fuente es un requisito previo para que se den las libertades 1 y 3. El código fuente son las líneas de código escritas en un lenguaje de programación, las cuales nos sirven para ver cómo están construidas las instrucciones del programa y es posible hacer modificaciones (al código) de acuerdo a las propias necesidades, claro, respetando la licencia de software en cuestión. No hay necesidad de avisarle o pedirle permiso a alguien por haber hecho tales mejoras al código. Si consideras que estas modificaciones pueden ser importantes para el funcionamiento de la aplicación, tienes la libertad de publicarlos para que otras personas puedan beneficiarse de estas mejoras. Si tienes el código fuente puedes convertirlo a código ejecutable (binario) por medio de un compilador o interprete de ese lenguaje de programación. Este código ejecutable es el que instalas en la computadora y correrlo con el click del ratón.
El software propietario, shareware, freeware, entre otros, no te dan la libertad de acceder al código fuente, por lo tanto no puedes hacerle mejoras ya que sólo te entregan el código binario o ejecutable, el cual no puedes modificar, y si intentas modificarlo (lo cual es imposible) te puedes meter en problemas legales. El software propietario te restringe a un más, ya que ni siquiera puedes distribuirlo o copiarlo ya que las licencias, en la mayoría de los casos, están restringidas por usuario.
Para que las libertades de hacer modificaciones y de publicar versiones mejoradas tengan sentido, debes tener acceso al código fuente del programa. Por lo tanto, la posibilidad de acceder al código fuente es una condición necesaria para el software libre. Si el software no cumple con las 4 libertades, mencionadas anteriormente, entonces no es software libre.
7.1.5 Las licencias de software.
Las licencias de software es la autorización, permiso o contrato por escrito concedido por el titular de los derechos de autor o propiedad intelectual del programa informático, al usuario de dicho software. En la licencia se establecen restricciones de uso, modificación o redistribución del software. También se señalan los límites de la licencia como el plazo de duración, el territorio de aplicación y todas las demás cláusulas que el titular de los derechos de autor establezca.
- BSD (Berkeley Software Distribution)
- MPL (Mozilla Public License)
- GPL (General Public License)
De estas tres, la licencia GPL de la GNU es la más utilizada por los proyectos de software libre. La licencia GPL está basada por el concepto “copyleft” (contrario a copyright), el cual es una manera de distribuir el software, mientras no entren en conflicto con las libertades centrales. Copyleft es una regla o tipo de licencia que implica que, cuando se redistribuya el programa, no se pueden agregar restricciones para denegar a otras personas las (4) libertades centrales. El proyecto GNU utiliza a “copyleft” como su bandera para proteger de modo legal estas libertades para todos. En otras palabras, si creaste o modificaste unas líneas de código de un software libre, no debes de poner restricciones adicionales si distribuyes tal software. Muchas compañías, por ejemplo, toman el código fuente (con licencia GPL), el cual está disponible gratuitamente en Internet. Después lo modifican de acuerdo a sus necesidades, y al momento que distribuyen el programa, no proporcionan el código fuente, además ponen otras restricciones. Esto viola la licencia GPL basada en el concepto copyleft.
7.1.5.1 Free Software vs. Open Source.
En 1998, aparece un nuevo movimiento en el mundo del software, el cual se dice llamar Open Source o Código Abierto y es impulsado por la Open Source Initiative (www.opensource.org). Aunque el Software Libre y el Open Source parecen similares, tienen distintas filosofías creando mucha confusión entre los usuarios y desarrolladores. La Free Software Foundation deja claro que “el movimiento del software libre y el movimiento Open Source son como dos partidos políticos en nuestra comunidad”. Open Source describe una categoría de licencias de software casi, pero no completamente, igual que software libre. Muchas personas creen que si algún software te ofrece el código fuente, es Open Source. Sin embargo, mucho de este software catalogado como Open Source, aunque te da la libertad de modificar el código fuente, no da la libertad de distribuir sus modificaciones. En algunas ocasiones puedes hacerlo, siempre y cuando, notifiques por escrito al titular del software. En muchas de las ocasiones restringen el uso comercial de éste.
En resumen, Open Source y Free Software son dos movimientos distintos con diferentes filosofías. Por un lado el Software Libre hace énfasis en que todos los programadores y desarrolladores tienen la obligación ética de respetar las 4 libertades, y por el otro lado, la corriente Open Source intenta convencer a las empresas de que pueden obtener beneficios respetando la libertad de sus usuarios al intercambiar y compartir sus programas. Aunque son movimientos distintos, ambos luchan contra su principal enemigo, el software propietario.
Proyectos de software libre.
Existen en la red de Internet una infinidad de proyectos de software libre y open source que pueden ser utilizados para distintos propósitos. Nada más en el sitio SourceForge.net existen más de 157 mil proyectos registrados. Cuando uno hace uso de estas aplicaciones, como usuario, se da cuenta de las bondades del modelo de bazar, en donde muchos desarrolladores alrededor del mundo aportan sus conocimientos para seguir mejorando continuamente estos programas. Muchas de estos proyectos están desarrollados en lenguajes tales como C, C++, Java, PHP, Javascript, etc, y utilizan la licencia GNU/GPL la cual ofrece más libertades para los usuarios y desarrolladores.
A continuación listo una serie de proyectos los cuales pueden ser descargados gratuitamente en las ligas de Internet que se mencionan, los cuales pueden ser utilizados por personas o webmasters que quieran enriquecer sus páginas web.
Sistemas Administradores de Contenido:
- Joomla (www.joomla.org)
- Mambo (www.mambo-foundation.org)
- PHP Nuke (www.phpnuke.org)
- PHP WCMS (www.phpwcms.de)
- PostNuke (www.postnuke.com)
Foros de discusión:
- phpBB (www.phpbb.com)
Blogs:
- B2evolution (www.b2evolution.net)
- Nucleus CMS (nucleuscms.org)
- WordPress (www.wordpress.com)
Listas de Correo:
- PHP List (www.phplist.com)
Administradores de proyectos:
- dotProject (www.dotproject.net)
- PHProjekt (www.phprojekt.com)
Wikis
- TikiWiki (www.tikiwiki.org)
- TikiWiki (www.tikiwiki.org)
- PhpWiki (phpwiki.sourceforge.net)
Comercio electrónico.
- OS Commerce (www.oscommerce.com)
- Zen Cart (www.zen-cart.com)
Tipos de Software Software libre: Es aquel software que te permite la libertad de usarlo, copiarlo, distribuirlo, y como se te proporciona el código fuente, puedes estudiarlo, mejorarlo y adaptarlo a tus necesidades libremente, sin pagar o permisos a nadie. El hecho de que sea libre no significa que no puedas cobrar por la distribución o modificaciones al software, siempre y cuando no pongas restricciones adicionales, respetando las 4 libertades y el concepto de copyleft. Software propietario: Es el tipo de software en el cual su uso, redistribución o modificación está prohibida, o se requiere que se solicite autorización al titular de los derechos de la propiedad intelectual. La gran mayoría de este software tiene un costo económico por adquirirlo, convirtiéndose en software propietario comercial. No se proporciona el código fuente, por lo que no puedes hacerle modificaciones al mismo. Freeware: es una forma de comercialización. No debe confundirse freeware con free software, son términos muy distintos. Freeware es todo aquel programa que se distribuye gratuitamente, sin ningún costo adicional. La diferencia más importante entre ambos es que el freeware no se te proporciona el código fuente en la mayoría de los casos, sólo el ejecutable. Por lo tanto, no puedes modificarlo. Shareware: es una modalidad de comercialización más extendida. Este software si tiene costo y desde luego no se te proporciona el código fuente. El programa viene en varias modalidades: como una versión de demostración con funciones o características limitadas o con un uso restringido en tiempo, por ejemplo 30 días. Esta modalidad le brinda al usuario probar el software antes de comprarlo, y posteriormente, si es del agrado, comprar la versión completa del programa. Adware: Es software gratuito que contiene anuncios, si deseas comprar la versión completa sin anuncios, tienes que pagar una cantidad de dinero por adquirirla. Al igual que el freeware, shareware y el software propietario, el adware no te proporcionan el código fuente. Las formas de distribución del software que utilizan el freeware, shareware y adware, sólo afectan la forma en que los programas son comercializados, y son independientes de la licencia de software a la que pertenezcan. |
En la tercera parte de este artículo hablaremos sobre el futuro del software libre y abordaremos también el controversial tema de las patentes de software y su impacto en la industria del desarrollo de programas de cómputo.
Evelio Martínez Martínez y Orlando Jorge Franco Murillo y son: profesor-investigador y estudiante respectivamente de la carrera de Licenciado en Ciencias Computacionales, perteneciente a la Facultad de Ciencias de la Universidad Autónoma de Baja California (UABC) en la ciudad de Ensenada. Se les puede contactar en evelio(at)uabc.mx y duende. estudio(at)gmail.com
7.2 Futuro del Software Libre
Hace solamente unos cinco años, el software libre (llámese open source, free software, etc.) era todavía una curiosidad, algo que algunas empresas arriesgadas estaban probando y que muchas otras consideraban cosa de comunistas y de locos que regalaban su trabajo. Hoy en día, el software libre se ha establecido como una verdadera alternativa para empresas de diferentes tallas, desde las micro hasta las más grandes empresas de la talla de IBM.
Solamente los pocos informados, o los que ven sus intereses afectados, siguen desdeñando al software libre y poniéndolo en un plano inferior al software comercial. Sin embargo, la inserción del software libre en un ambiente de fuertes intereses comerciales no ha carecido de situaciones ríspidas y de tropiezos. Con estas experiencias cabe preguntarse si estos problemas seguirán presentes o incluso se amplificarán, o bien si hay soluciones que resulten convenientes para todas las partes involucradas.
En esta tercera parte del artículo de software libre hablaremos sobre el tema controversial de las patentes de software y su impacto en la industria del desarrollo de programas, también abordaremos el futuro del software libre y las virtudes de la nueva licencia GPL versión 3.
¿Qué es una patente?.
Una patente es un derecho exclusivo concedido a una invención, es decir, un producto o procedimiento que aporta, en general, una nueva manera de hacer algo o una nueva solución técnica a un problema. La patente proporciona protección para la invención al titular de la misma. La protección de una patente se concede durante un período limitado que suele ser de 20 años.
El término patente deriva del latin patens, -entis, que originalmente tenía el significado de estar abierto, o descubierto (a inspección pública) y de la expresión letras patentes, que eran decretos reales que garantizaban derechos exclusivos a determinados individuos en los negocios. Siguiendo la definición original de la palabra, una de las finalidades de la legislación sobre las patentes es la de inducir al inventor a revelar sus conocimientos para el avance de la sociedad a cambio de la exclusividad durante un periodo limitado de tiempo. Luego una patente garantiza un monopolio de explotación de la idea o de una maquinaria durante un cierto tiempo.
¿Las patentes de software?.
La ley de la propiedad industrial en México, promulgada por el Instituto Mexicano de Propiedad Industrial (IMPI), en su artículo 15 dice textualmente “Se considera invención toda creación humana que permita transformar la materia o la energía que existe en la naturaleza, para su aprovechamiento por el hombre y satisfacer sus necesidades concretas”. En el artículo 19 fracción IV de esta misma ley dice lo siguiente: “No se considerán invenciones para los efectos de esta Ley, los programas de computación”. Lo que queda bien claro, es que la legislación mexicana permite que se patenten inventos, más no el software.
Afortunadamente en México los programas de computación son considerados como si fueran obras del intelecto, protegidos por la Ley Federal del Derecho de Autor en su artículo 13. Pero en otros países, notablemente en los Estados Unidos (EUA), los programas y herramientas de software se patentan como si fueran inventos, y esto trae una infinidad de problemas para la industria del software en general, tal como veremos más adelante.
Una patente puede verse como un monopolio sobre una tecnología. Los monopolios a lo largo de la historia han traído estragos económicos y sociales que no son bien vistos en la sociedad. Las patentes de software van en contra de la filosofía del movimiento de software libre. Es por eso que la legislación sobre patentes debe de ser estudiada con cuidado, de manera que no afecte intereses de los usuarios y desarrolladores de software.
Las patentes de software inhiben el desarrollo de programas de cómputo y prácticamente destruyen a los pequeños grupos de desarrollo, los cuales no pueden luchar contra los grandes monopolios del software. Las patentes están convirtiendo la publicación del software en el privilegio de algunos pocos. Solamente las grandes corporaciones de la industria del software podrían sobrevivir al embate por las demandas jurídicas y otros costos adicionales, que los grupos pequeños de desarrolladores no podrían afrontar. El problema, como siempre con las patentes, es que si te demandaran, descansa sobre tí la necesidad de demostrar que la patente en cuestión es inválida.
Un ejemplo típico de una patente de software es la No. 6,727,830 conocida como “double click” otorgada a la compañía Microsoft por la Oficina de Patentes de Estados Unidos en 2004. Esta patente es utilizada por todos nosotros cuando damos un click con nuestro ratón a un anuncio en una página Web, por ejemplo. Esto significa ¿Que todos los que hacemos esta acción estaríamos infringiendo esta patente?
Otro caso muy sonado en los medios electrónicos fue el de las compañías NTP vs RIM (Blackberry). La empresa canadiense Research in Motion (RIM), fabricante de los dispositivos móviles Blackberry, tuvo que pagar $612.5 millones de dólares a NTP, una pequeña compañía de Arlington (Virginia), para poner fin a un largo litigio. La disputa comenzó cuatro años atrás, cuando NTP acusó a RIM de violar cinco de sus patentes con su tecnología, que permite consultar el correo electrónico desde cualquier lugar, así como realizar llamadas de teléfono con la agenda electrónica. El pago de esa cantidad acaba con la demanda por uso de tecnologías patentadas y permitirá que la popular Blackberry pueda seguir usándose en EUA y otros países. Todos los teléfonos inteligentes (smartphones) utilizan la agenda electrónica para establecer llamadas, es algo obvio, ¿no creen? Bueno a NTP se le ocurrió patentar esta idea o funcionalidad. Y lo curioso es que la compañía NTP ni siquiera está innovando en esta área.
Por otra parte Microsoft afirma que el kernel de Linux viola 42 de sus patentes, las interfaces gráficas de usuario 65, OpenOffice 45, los programas de correo electrónico 15 y otras utilidades libres violarían nada menos que 88 patentes. ¿Que tan cierto será esto? ¿Acaso todos los usuarios del software libre tenemos que pagarle regalías a Microsoft? A este respecto, la organización OIN (Open Invention Network) ha retado a Microsoft para que muestre evidencias de las patentes que dicen tener y que están siendo violadas, pues argumentan que se trata solamente de un ardid mercadotécnico por parte de Microsoft. Por cierto, OIN opera de una manera interesante, pues compra patentes y permite su uso libre a las empresas que se comprometan a no usar sus propias patentes para atacar proyectos de código abierto; actualmente la organización cuenta con un cúmulo de patentes que vale millones de dólares.
Un hecho histórico ocurrió recientemente en la Corte de Distrito de Manhattan, The Software Freedom Law Center demandó a la empresa californiana Monsoon Multimedia por infringir la licencia GLP versión 2. Este es el primer juicio en los Estados Unidos que busca aplicar la ley a favor de los derechos de protección de las licencias que rigen muchos proyectos de software libre. Monsoon es acusado de utilizar código fuente de BusyBox (www.busybox.net) -una utilería de código abierto frecuentemente incluida con Linux- en su tecnología de video digital, los cuales son incorporados en productos de grandes compañías como Intel, Microsoft y Panasonic. Moonson violó la licencia GPLv2 al no proporcionar los cambios hechos al código fuente, así como el código fuente donde aparecen estos cambios a otros desarrolladores de software libre. Este es sólo un ejemplo que se suma a muchos otros casos donde compañías de software toman el código fuente de proyectos de software libre, el cual está disponible abiertamente en internet y con licencia GPL, para utilizarlo en sus desarrollos de software sin respetar lo estipulado en la misma licencia. Otro caso muy sonado en años recientes, que utilizaron esta misma práctica, es el dispositivo grabador de video digital TiVo.
Hay que recordar que si alguien libera el fruto de su trabajo con la licencia GPL básicamente está diciendo “aquí va el código fuente, puedes usarlo a tu conveniencia, pero igualmente debes compartirlo si lo modificas o distribuyes en cualquier forma”. Y ahí es precisamente donde han roto el acuerdo varias compañías, pues han usado trabajo con licencia GPL, lo han modificado, pero no han querido compartir el código fuente resultante. La mas reciente versión de la licencia GPL, la versión 3, ha sido diseñada para que no sucedan casos como el de Tivo, donde el dispositivo automáticamente se apaga si detecta que su software ha sido modificado; en otras palabras, donde los fabricantes del equipo decidieron que ellos si podían hacer uso de las libertades provistas por el software, pero que tu no.
Por consiguiente el software libre tiene un gran futuro por delante. Hay cada vez más adeptos que apoyan este movimiento liberador del software. Hay infinidad de razones por las que el software libre tiene muchas ventajas sobre el software propietario.
Beneficios tecnológicos: El software libre ha demostrado a lo largo de los años ser seguro, estable y poderoso para aplicaciones con múltiples usuarios y registros. La curva del aprendizaje cada vez más se está aminorando, las nuevas aplicaciones y distribuciones con interfaz gráfica permiten a los usuarios novatos introducirse al mundo del software libre.
Beneficios económicos: El software libre es más barato y en la mayoría de los casos, no tienes que pagar ningún centavo. Las empresas, instituciones o usuarios no tienen que pagar grandes cantidades de dinero por las licencias.
Beneficios culturales: El software libre promueve la mezcla de culturas. El modelo de bazar que utiliza el software libre permite que desarrolladores de muchos países con diversas religiones, culturas y costumbres, puedan compartir sus conocimientos para un sólo fin.
Muchas empresas de software propietario han criticado la manera de como se desarrolla el software libre. Dicen, entre otras cosas, que cómo es posible que se confie en un software que no tiene ninguna garantía por parte del creador. Cuando en los contratos (licencias) de software propietario tampoco se hacen responsables por daños económicos, y de otros tipos por el uso de sus programas.
Mark Driver, vicepresidente de la consultora tecnológica Gartner, durante la conferencia Open Source Summit 2007 de Las Vegas, pronosticó que “dentro de poco más de 3 años el 80% del software comercial contendrá cantidades significativas de Código Abierto, seamos o no conscientes de ello”. “El software libre va a entrar en tu red quieras o no; es prácticamente imposible evitarlo”, dijo Driver. En su conferencia, Driver también explicó que el software abierto no es tan malo como quieren hacer creer sus detractores ni tan bueno como afirman sus defensores. Lo realmente importante es trazar un plan para determinar en qué campos puede ser útil su aplicación: es mejor evitar por completo su uso que hacerse el sueco y no supervisar su adopción. Esto significa que las empresas desarrolladoras de software propietario, aman el software libre, pero no quieren aceptarlo.
La Licencia GPL v3 sale al rescate.
Después de meses de debate y deliberaciones, la tan esperada versión 3 de la licencia GPL fue presentada. GPL (General Public Licence) es una de las licencias más importantes que protegen al software libre y varios proyectos de Open Source. La versión 3 de esta licencia sigue garantizando las mismas libertades al usuario de usar, copiar, distribuir, etc. Lo más trascendente de GLP v3 es que intenta solucionar los problemas que la comunidad de software libre ha tenido que enfrentar, con respecto al tema de las patentes de software. Ahora los proyectos de software con GPL v3 estarán más protegidos en este aspecto; por ejemplo, si se da el caso que de una empresa utilice software y piezas de código con esta licencia, ésta ofrecerá permiso gratuito para utilizar las patentes que lo cubren al resto de los usuarios. También la licencia contempla el caso cuando el código se encuentre en un dispositivo de hardware de manera embebido.
Ahora lo único que falta es que las licencias de software de las distintas empresas, protegidas con versiones anteriores de la licencia GPL, se actualicen a la versión 3 y así se protejan contra las empresas de software depredadoras.
Cabe decir que la licencia GPL no es la única que protege al código abierto, pero ciertamente es una de las más utilizadas. En cuanto a la versión 3, aún es temprano para decir qué futuro tendrá, pues de momento está recibiendo una acogida muy tibia por parte de los desarrolladores y no han faltado críticos que digan que muchos van a migrar de ella hacia otra licencia mas “amigable” o menos prohibitiva, como la de BSD.

8.1 UML.
UML (Unified Modeling Language) es un lenguaje que permite modelar, construir y documentar los elementos que forman un sistema software orientado a objetos. Se ha convertido en el estándar de facto de la industria, debido a que ha sido impulsado por los autores de los tres métodos más usados de orientación a objetos: Grady Booch, Ivar Jacobson y Jim Rumbaugh. Estos autores fueron contratados por la empresa Rational Software Co. para crear una notación unificada en la que basar la construcción de sus herramientas CASE. En el proceso de creación de UML han participado, no obstante, otras empresas de gran peso en la industria como Microsoft, Hewlett-Packard, Oracle o IBM, así como grupos de analistas y desarrolladores.
Esta notación ha sido ampliamente aceptada debido al prestigio de sus creadores y debido a que incorpora las principales ventajas de cada uno de los métodos particulares en los que se basa (principalmente Booch, OMT y OOSE). UML ha puesto fin a las llamadas “guerras de métodos” que se han mantenido a lo largo de los 90, en las que los principales métodos sacaban nuevas versiones que incorporaban las técnicas de los demás. Con UML se fusiona la notación de estas técnicas para formar una herramienta compartida entre todos los ingenieros software que trabajan en el desarrollo orientado a objetos.

Uno de los objetivos principales de la creación de UML era posibilitar el intercambio de modelos entre las distintas herramientas CASE orientadas a objetos del mercado. Para ello era necesario definir una notación y semántica común. En la Figura 2 se puede ver cuál ha sido la evolución de UML hasta la creación de UML 1.3, en el que se basa este documento. Hay que tener en cuenta que el estándar UML no define un proceso de desarrollo específico, tan solo se trata de una notación. En este curso se sigue el método propuesto por Craig Larman [Larman99] que se ajusta a un ciclo de vida iterativo e incremental dirigido por casos de uso.
En la parte II de este texto se expone la notación y semántica básica de UML, en la parte III se presentan conceptos avanzados de la notación UML, mientras que en la parte IV se presenta el método de desarrollo orientado a objetos de Larman, que se sirve de los modelos de UML que se han visto anteriormente.
8.1.1 ¿Porqué es importante UML ?
Hoy en día, UML ("Unified Modeling Language") está consolidado como el lenguaje estándar en el análisis y diseño de sistemas de cómputo. Mediante UML es posible establecer la serie de requerimientos y estructuras necesarias para plasmar un sistema de software previo al proceso intensivo de escribir código.
En otros términos, así como en la construcción de un edificio se realizan planos previo a su construcción, en Software se deben realizar diseños en UML previa codificación de un sistema, ahora bien, aunque UML es un lenguaje, éste posee más características visuales que programáticas, mismas que facilitan a integrantes de un equipo multidisciplinario participar e intercomunicarse fácilmente, estos integrantes siendo los analistas, diseñadores, especialistas de área y desde luego los programadores.
8.1.2 Complejidad / Objetos
Entre más complejo es el sistema que se desea crear más beneficios presenta el uso de UML ("Unified Modeling Language"), las razones de esto son evidentes, sin embargo, existen dos puntos claves : El primero se debe a que mediante un plano/visión global resulta más fácil detectar las dependencias y dificultades implícitas del sistema, y la segunda razón radica en que los cambios en una etapa inicial (Análisis) resultan más fáciles de realizar que en una etapa final de un sistema como lo sería la fase intensiva de codificación.
Puesto que UML es empleado en el análisis para sistemas de mediana-alta complejidad, era de esperarse que su base radique en otro paradigma empleado en diseños de sistemas de alto nivel que es la orientación a objetos, por lo que para trabajar en UML puede ser considerado un pre-requisito tener experiencia en un lenguaje orientado a objetos.
8.2. ¿QUE ES RUP?
RUP es un proceso de desarrollo de software:
Forma disciplinada de asignar tareas y responsabilidades en una empresa de desarrollo (quién hace qué, cuándo y cómo).
Objetivos:
Asegurar la producción de software de calidad dentro de plazos y presupuestos predecibles. Dirigido por casos de uso, centrado en la arquitectura, iterativo (mini-proyectos) e incremental (versiones).
Es también un producto:
Desarrollado y mantenido por Rational.
Actualizado constantemente para tener en cuenta las mejores prácticas de acuerdo con la experiencia.
Aumenta la productividad de los desarrolladores mediante acceso a:
Base de conocimiento
Plantillas
Herramientas
Se centra en la producción y mantenimiento de modelos del sistema más que en producir documentos.
RUP es una guía de cómo usar UML de la forma más efectiva.
RUP pretende implementar las mejores prácticas actuales en ingeniería de software:
Desarrollo iterativo del software
Administración de requerimientos
Uso de arquitecturas basadas en componentes
Modelamiento visual del software
Verificación de la calidad del software
Control de cambios.
8.2.4 Ciclos y fases.

8.2.5 Gráfico: Fases de RUP.
RUP divide el proceso de desarrollo en ciclos, teniendo un producto al final de cada ciclo.
Cada ciclo se divide en cuatro Fases:
Inicio
Elaboración
Construcción
Transición
Cada fase concluye con un hito bien definido donde deben tomarse ciertas decisiones.
8.3 DEFINICIÓN DE CRM.
CRM (Customer Relationship Management) es un término que sin duda está de moda. Actualmente hay frecuentes conferencias y publicaciones, que tratan el tema desde diversos puntos de vista. Desde la Asociación Española de Marketing Relacional hemos observado esta diversidad de opiniones sobre qué es CRM y qué abarca. Por ello, la AeMR quiere ofrecer una definición de CRM, que sirva como referente para los profesionales del sector.
CRM o Gestión de Relaciones con el Cliente.
Es el conjunto de estrategias de negocio, marketing,comunicación e infraestructuras tecnológicas, diseñadas con el objetivo de construir una relación duradera con los clientes, identificando, comprendiendo y satisfaciendo sus necesidades.
CRM va más allá del marketing de relación, es un concepto más amplio, es una actitud ante los clientes y ante la propia organización, que se apoya en procesos multicanal (teléfono,internet, correo, fuerza de ventas,...) para crear y añadir valor a la empresa y a sus clientes.
Seguidamente se definen los principales términos que se utilizan relacionados con el marketing relacional y /o CRM.
Call Center : Centro de atención de llamadas.
Contact Center : Centro de atención multicanal (llamadas, mails,...).
Data Mining : Proceso de análisis de la información disponible en el Data Warehousing.
Data Warehousing : Almacén de la información de la compañía sobre clientes, productos, competencia,....para permitir el análisis y acceso a la misma desde los distintos ámbitos de una actividad de negocio (ventas , producción, marketing...etc.).
e-CRM: Gestión de las relaciones con los clientes utilizando el canal de Internet.
Fuerza de Ventas : Equipo comercial (vendedores) de una empresa.
Gestión del conocimiento : La gestión y análisis de la información, experiencias, mejoras, prácticas,que existe en una empresa.
Mailing : Envío de diversos tipos de comunicaciones a través del correo a un público previamente definido e identificado.
Marketing Relacional : Acciones de conquista y programas de fidelización que basan su estrategia en el análisis de los datos del cliente y en una comunicación one-to-one.
Medios Tradicionales : Canales de comunicación usados por los anunciantes para difundir sus mensajes publicitarios como son la prensa, la radio, la televisión, el vídeo o el cine.
Outsourcing :Es la externalización de actividades de la empresa como la informática.
Planificación Integral de Recursos en CRM : Modelo organizativo de gestión empresarial que integra las funciones administrativas/financieras, logística, producción y gestión de los recursos humanos, sitúando al cliente en la posición central de forma que los procesos de la empresa se orientan a él.
8.4 ¿QUÉ ES BPM?
Esta sigla significa Gestión de Procesos de Negocio (BPM – Business Process Management) a “la metodología empresarial cuyo objetivo es mejorar la eficiencia a través de la gestión sistemática de los procesos de negocio, que se deben modelar, automatizar, integrar, monitorizar y optimizar de forma continua. Como su nombre sugiere, BPM se enfoca en la administración de los procesos del negocio”.
Las empresas necesitan constantemente adaptar y mejorar sus procesos, pero frecuentemente están frenadas por aplicaciones y sistemas que no están preparados para explotar nuevas oportunidades y adaptarse a los cambios de forma ágil. El BPM, con sus enfoques evolucionados y sus tecnologías punta, ha emergido como el elemento clave para proveer a las organizaciones de la “Agilidad” y “Flexibilidad” necesaria para responder de forma rápida a los nuevos cambios y oportunidades de mercado.
Es un conjunto de recursos y actividades interrelacionados que transforman elementos de entrada en elementos de salida. Los recursos pueden incluir personal, finanzas, instalaciones, equipos, técnicas y métodos.
A través del modelado de las actividades y procesos puede lograrse un mejor entendimiento del proceso y muchas veces esto presenta la oportunidad de mejorarlos. La organización de los procesos reduce errores, asegurando que los procesos se comporten siempre de la misma manera, reduciendo el margen de error y dando elementos que permitan visualizar el estado de los mismos durante cada etapa. La administración de los procesos permite asegurar que los mismos se ejecuten eficientemente, cumpliendo con estándares de calidad previamente establecidos, y ayudando a la obtención de información que luego puede ser usada para mejorarlos. Es a través de la información que se obtiene de la ejecución diaria de los procesos, que se puede identificar posibles ineficiencias o fallas en los mismos, y actuar sobre ellos para optimizarlos.
Para soportar esta estrategia es necesario contar con un conjunto de herramientas que den el soporte necesario para cumplir con el ciclo de vida de BPM. Este conjunto de herramientas son llamadas Business Process Management System (BPMS), y con ellas se construyen aplicaciones BPM.
Existen diversos motivos que mueven la gestión de los Procesos dentro de una organización, entre los cuales se encuentran:
Extensión del programa institucional de calidad
Cumplimiento de legislaciones vigentes
Crear nuevos y mejores procesos (mejoramiento continuo)
Entender qué se está haciendo bien o mal a través de la comprensión de los procesos
Documentar los procesos para la subcontratación y la definición del Service Level Agreement (SLA)
Automatización y organización de los procesos
Crear y mantener la cadena de valor.
8.5 LAS HERRAMIENTAS CASE.
Las herramientas CASE (Computer Aided Software Engineering, Ingeniería de Software Asistida por Computadora) son diversas aplicaciones informáticas destinadas a aumentar la productividad en el desarrollo de software reduciendo el coste de las mismas en términos de tiempo y de dinero. Estas herramientas nos pueden ayudar en todos los aspectos del ciclo de vida de desarrollo del software en tareas como el proceso de realizar un diseño del proyecto, cálculo de costes, implementación de parte del código automáticamente con el diseño dado, compilación automática, documentación o detección de errores entre otras.
Sistema de software que intenta proporcionar ayuda automatizada a las actividades del proceso de software. Los sistemas CASE a menudo se utilizan como apoyo al método.
8.5.1 Objetivos.
Mejorar la productividad en el desarrollo y mantenimiento del software.
Aumentar la calidad del software.
Reducir el tiempo y coste de desarrollo y mantenimiento de los sistemas informáticos.
Mejorar la planificación de un proyecto
Aumentar la biblioteca de conocimiento informático de una empresa ayudando a la búsqueda de soluciones para los requisitos.
Automatizar el desarrollo del software, la documentación, la generación de código, las pruebas de errores y la gestión del proyecto.
Ayuda a la reutilización del software, portabilidad y estandarización de la documentación
Gestión global en todas las fases de desarrollo de software con una misma herramienta.
Facilitar el uso de las distintas metodologías propias de la ingeniería del software.
8.5.2 Clasificación.
Aunque no es fácil y no existe una forma única de clasificarlas, las herramientas CASE se pueden clasificar teniendo en cuenta los siguientes parámetros:
Las plataformas que soportan.
Las fases del ciclo de vida del desarrollo de sistemas que cubren.
La arquitectura de las aplicaciones que producen.
Su funcionalidad.
La siguiente clasificación es la más habitual basada en las fases del ciclo de desarrollo que cubren:
Upper CASE (U-CASE), herramientas que ayudan en las fases de planificación, análisis de requisitos y estrategia del desarrollo, usando, entre otros diagramas UML.
Middle CASE (M-CASE), herramientas para automatizar tareas en el análisis y diseño de la aplicación.
Lower CASE (L-CASE), herramientas que semi-automatizan la generación de código, crean programas de detección de errores, soportan la depuración de programas y pruebas. Además automatizan la documentación completa de la aplicación. Aquí pueden incluirse las herramientas de Desarrollo rápido de aplicaciones.
Existen otros nombres que se le dan a este tipo de herramientas, y que no es una clasificación excluyente entre sí, ni con la anterior:
Integrated CASE (I-CASE), herramientas que engloban todo el proceso de desarrollo software, desde análisis hasta implementación.
MetaCASE, herramientas que permiten la definición de nuestra propia técnica de modelado, los elementos permitidos del metamodelo generado se guardan en un repositorio y pueden ser usados por otros analistas, es decir, es como si definiéramos nuestro propio UML, con nuestros elementos, restricciones y relaciones posibles.
CAST (Computer-Aided Software Testing), herramientas de soporte a la prueba de software.
IPSE (Integrated Programming Support Environment), herramientas que soportan todo el ciclo de vida, incluyen componentes para la gestión de proyectos y gestión de la configuración.
Por funcionalidad podríamos diferenciar algunas como:
Herramientas de generación semiautomática de código.
Editores UML.
Herramientas de Refactorización de código.
Herramientas de mantenimiento como los sistemas de control de versiones.
8.6 Técnicas de Programación Orientadas a Objetos.
El paradigma de la orientación a objetos ha logrado una gran difusión en el área de análisis de sistemas de información. Han sido propuestas diversas técnicas de Análisis Orientado a Objetos (AOO), muchas de ellas ya documentadas en la forma de libros. Para el lector no familiarizado con esta área le es tremendamente difícil distinguir, de entre la gran variedad de propuestas, cuáles son los aspectos efectivamente relevantes y diferenciadores de cada propuesta. Para permitir una comparación entre las técnicas de AOO es necesario establecer un sistema de clasificación que destaque propiedades comunes de las diferentes técnicas.
En la literatura es posible encontrar algunas formas muy generales de clasificar técnicas de AOO. En [Capretz&Lee92] se propone una clasificación que distingue dos direcciones en las técnicas de orientación a objetos. Una es la adaptación, donde técnicas establecidas y conocidas de desarrollo estructurado de sistemas son combinadas para formar una nueva técnica de AOO. La otra corresponde a la asimilación, donde la tendencia es modificar solamente las técnicas de análisis, diseño y implementación para la orientación a objetos, preservando eso sí las líneas básicas del ciclo de vida tradicional. En [Monarchi&Puhr92] se describe una clasificación que utiliza como criterio básico la forma y el grado en que las técnicas orientadas a objetos incorporan otros paradigmas. Son identificados tres enfoques:
Enfoque Combinativo: Es aquél en que diferentes técnicas son usadas para modelar diferentes perspectivas de la realidad (estática, funcional y de control).
Enfoque Adaptativo: Es aquél en que las técnicas existentes son usadas de una nueva manera (orientada a objetos), o extendidas para incluir la orientación a objetos. En este enfoque es posible adaptar procedimientos y notaciones que ya probaron ser útiles, en la perspectiva del nuevo paradigma.
Enfoque Puro: Es aquel en que nuevas técnicas son concebidas para modelar la multidimensionalidad de la orientación a objetos.
En el presente trabajo se define una clasificación más amplia y dirigida específicamente al problema de la comparación de técnicas de AOO.
8.6.1 Las Perspectivas Del AOO.
En el contexto del desarrollo de sistemas de software con orientación a objetos, se entiende por Análisis Orientado a Objetos al proceso de construcción de modelos del dominio del problema, identificando y especificando un conjunto de objetos semánticos que interactúan y se comportan de acuerdo a los requerimientos del sistema. Los objetos semánticos son aquellos que poseen un significado específico en el dominio del problema, según [Monarchi&Puhr92].
De acuerdo a esta definición, el AOO es esencialmente basada en modelado. Es razonable esperar entonces, que la especificación resultante de la aplicación de técnicas de AOO resulte en múltiples modelos y múltiples notaciones. En esta perspectiva, el proceso de construcción de los modelos del dominio del problema debe considerar diferentes aspectos o puntos de vista. Estos aspectos constituyen
las dimensiones del modelado orientado a objetos.
El modelado orientado a objetos comprende, como mínimo, dos aspectos relativamente ortogonales o dimensiones para describir un sistema complejo: la dimensión estructural de los objetos y la dimensión dinámica del comportamiento. Puede ser considerada también una dimensión adicional: la dimensión funcional de los requerimientos.
La dimensión estructural de los objetos se centra en el aspecto estático o pasivo. Está relacionada con la estructura estática de los objetos que forman parte del sistema. La estructura incluye la identidad de cada objeto, su clasificación, su encapsulamiento (sus atributos y sus operaciones) y sus relacionamientos estáticos (jerarquías de herencia, agregación, composición y asociaciones específicas).
La dimensión dinámica del comportamiento tiene que ver con el aspecto dinámico o activo, por esto describe el comportamiento y la colaboración de los objetos que constituyen el sistema. El comportamiento es reflejado por medio de estados (pasos dentro del ciclo de vida del objeto que caracterizan comportamientos diferentes del mismo), transiciones entre estos estados, eventos (hechos que ocurren y que producen las transiciones) y acciones (representadas por los métodos de los objetos, pudiendo ocurrir durante las transiciones o durante la permanencia en los estados). La colaboración es representada por modelos que muestran el flujo de eventos o mensajes entre los objetos. Así algunas acciones generadas en un objeto pueden gatillar transiciones, bajo la forma de eventos, en otros objetos.
8.6.2 Principal Fortaleza de las Técnicas de AOO.
El aspecto más consolidado en la mayoría de las técnicas y que constituye su principal fortaleza es el modelado de la dimensión estructural de los objetos. Como fue indicado anteriormente la causa de esto es que la mayoría de las propuestas utilizan los conceptos del modelado semántico en base a modelos extendidos entidad-relacionamiento. Estas técnicas poseen un desarrollo de más de 20 años a partir del trabajo original de [Chen76].
En este sentido la identificación y especificación de objetos, clases, métodos, atributos, asociaciones dependientes del dominio y jerarquías de herencia es la principal fortaleza de las técnicas de AOO.
Existe un intenso debate sobre el alcance que deben tener las patentes de software, o incluso sobre si deben existir. En nuestro país no hemos seguido (aún) a los Estados Unidos, en donde sí se puede patentar el software y donde se han dado casos muy ridículos al patentar mecanismos triviales y ampliamente usados. Algunos puntos candentes en el debate incluyen el determinar si el software es patentable y si las patentes de software alientan o desalientan la innovación. Es necesario apuntar que el software libre y el comercial pueden encontrar modelos de coexistencia muy benéficos, tal como han demostrado empresas como IBM, Oracle, Sun Microsystems y otras. El punto en esta discusión no es si el software debe o no ser comercial, sino el hecho de que patentar algoritmos y otras obras intelectuales puede limitar severamente la capacidad de los desarrolladores a realizar sistemas de relativa complejidad, pues seguramente usarán algún algoritmo que alguien ya patentó; así pues, las PyMES y desarrolladores independientes, quienes usualmente no tienen los recursos económicos para hacerse de un buen acervo de patentes, estarían en desventaja ante las grandes empresas que si lo tienen.
10. BIBLIOGRAFIA
Palazzesi Ariel , Copyright 2005-2011 NeoTeo - Revista de Tecnología, http://www.neoteo.com/el-software-del-futuro , consultada 10 de mayo de 2011.
·





{kind=link}
{kind=link}
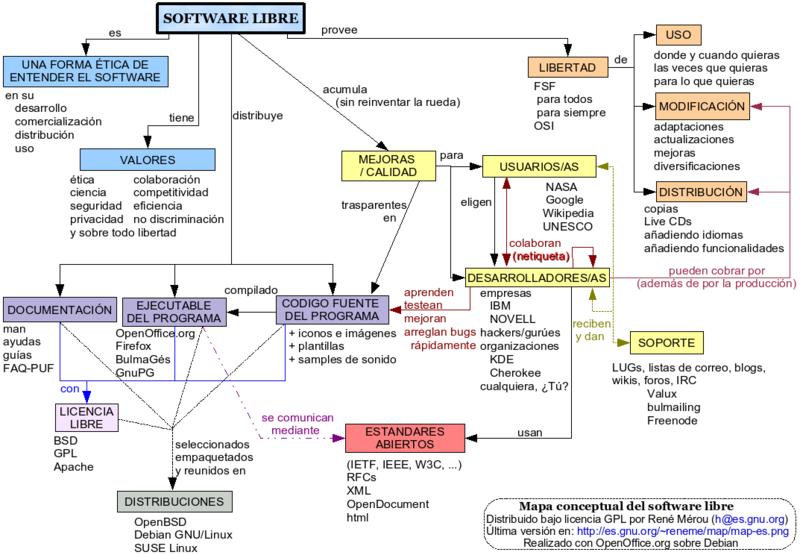{kind=link}
No hay comentarios:
Publicar un comentario